2013-14 Program on Computational Methods in Social Sciences (CMSS)
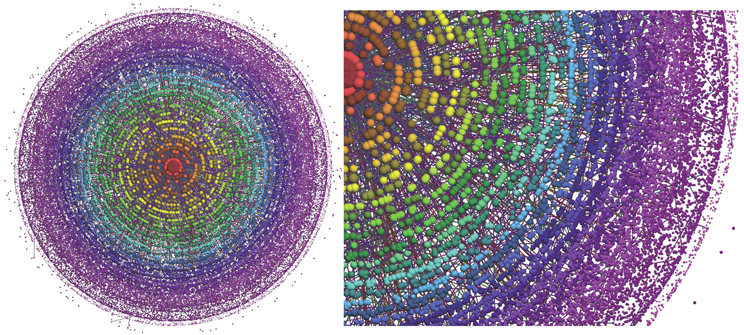 |
| Each node is a company in Finland c 2005-6 (universe of all companies). The size of each circle refers to the size of the firm (number of employees) it represents. The color refers to how many employees flow into and out of a company annually (labor turnover). An edge between two firms means that a worker has migrated from one company to another during the year (only 1% of edges are shown for readability). The graph is laid out so that companies that have had employees in common are near one another. Illustration by Omar Guerrero, Carnegie Mellon University, with permission from Robert Axtell. Created using the LaNet-vi software, http://lanet-vi.soic.indiana.edu/lanetvi.php |
Like many areas of the natural sciences, social sciences have experienced a “data explosion” in recent years. As a result, there is an increased focus among social scientists on statistical and computational methodology for handling social science datasets. Conversely, many statisticians and applied mathematicians have focused on social sciences in applications of their own work, especially in such fields as social networks and causal inference. New areas of social science research, such as the analysis of streaming data (survey data that are collected and analyzed in real time) have grown up motivated by the existence of suitable computational and statistical tools.
In addition to streaming and survey data, computer models for analyzing social infrastructure and networks are generating enormous data sets that must be analyzed. The data is often generated from multiple sources and contain complementary, but different, information that must be combined to gain a full understanding of the system. Extracting information from survey and computer generated data can be guided by new statistical and modeling approaches that can identify underlying structure and quantify the relative importance of different elements of the data sets.
This SAMSI program will bring together statisticians, computational mathematicians and social scientists to develop new methodology and applications in the context of modern social science datasets.
The structure of the program will revolve around three major areas where new statistical and computational methodology are being developed for social science problems: (a) social networks; (b) agent-based models; (c) new methodology for censuses and surveys. The three areas are not independent and there are many possibilities for interactions among them, for instance, in the use of network designs in surveys or in agent-based models as a tool for studying the evolution of dynamic social networks. Another likely theme is causal inference, which is a topic of interest in connection with all three of the major areas of the program.
Social network datasets pose particular problems for statistical inference because of the quadratic growth in the size of the network as a function of the number of nodes, and because of the high-order dependencies that are often needed to provide an adequate model of the network. Computational issues are critical even for static networks but are much more complex in the context of simulations for network dynamics. There is a need for understanding of network sampling methods, especially in the context of missing data. Expected themes include
- inferring causal relationships in social networks;
- respondent-driven sampling;
- event data as input for network models;
- clustering through latent variables and hierarchical models.
Agent-based modeling refers to models for social and economic data that track the behavior of each individual within a large complex system. Simulation-based analyses of these models are already widely used by social scientists, but have so far attracted only limited attention by mathematicians and statisticians. This program will focus on data assimilation, calibration, estimation and a variety of microeconometric, ecological inference, and multi-level modeling issues.
Statistical methodology for censuses and surveys is currently a very active field of research. Topics likely to be covered in the SAMSI program include:
- constructing complex models for survey data;
- statistical inference and asymptotics for survey data;
- imputing incomplete data: nonrandom nonresponse, measurement error, two-phase models, fractional imputation;
- combining data from multiple surveys, or from surveys with other forms of administrative data;
- monitoring and evaluating total survey error;
- confidentiality;
- spatial statistics, small area estimation and the incorporation of geographic information;
- inference from streaming data.
Description of Activities
Workshops
The program year will start with an Opening Workshop on August 18-22, 2013. There will be several mid-program workshops and a transition workshop during May, 2014. There may also be a summer school during June or July, 2013.
Courses
One or two semester-long graduate courses will be part of the CMSS program.
Working Groups
Working Groups will meet weekly throughout the program to pursue particular research topics, either identified at the Opening Workshop or subsequently chosen by the Working Group participants. Each Working Group consists of researchers associated with SAMSI---as on-site visitors, postdoctoral fellows, graduate students, or off-site participants---in addition to local faculty and scientists. These groups constitute the core of the scientific activities at SAMSI.
Opportunities to Participate
SAMSI is accepting applications from all who are interested in participating, including graduate students, postdocs, junior researchers, and faculty. Click here to see details and instructions for these opportunities.
Further Information
For additional information about the program, send e-mail to [email protected]